Atelier IA - La Correction automatique
2025-10-09
Certificat canadien en Humanités Numériques



Le correcteur est le chef d’orchestre de la fabrique du livre

Signes de correction ortho-typo
Les acteurs travaillent l’un après l’autre, faute après faute
La composition est un processus terriblement laborieux

La casse et la galée
Homogénéisation de la langue
Mouvement de standardisation de la langue reposant sur une sur-norme « légitimée et maintenue par tout un édifice de croyances sur la nature de la langue et sur ce qui est correct ou incorrect, croyances qui sont dictées inévitablement par les valeurs sociales et esthétiques de la société concernée. » (Lodge 1993)
- Problématique de l’« approche par défaut » (Paschalidis 2025)
- Prépondérance des données standardisées voire générées par des LLMs dans les données d’entraînement (Shumailov et al. 2024; Guo et al. 2024).
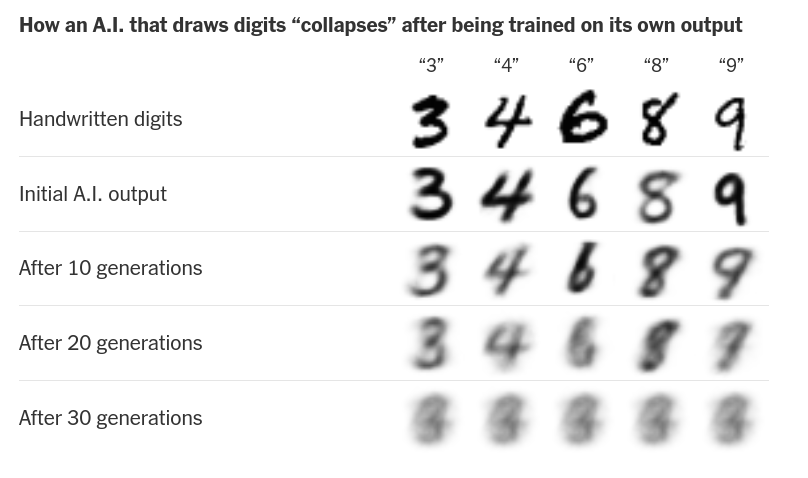

- Un idéal de clarté qui finit par s’auto-parodier (le fameux style chatgpt)
We show that while the core content of texts is retained when LLMs polish and rewrite texts, not only do they homogenize writing styles, but they also alter stylistic elements in a way that selectively amplifies certain dominant characteristics or biases while suppressing others - emphasizing conformity over individuality. By varying LLMs, prompts, classifiers, and contexts, we show that these trends are robust and consistent. (Sourati et al. 2025)
Des compétences poussées en ingénierie de prompts sont nécessaires pour contourner les effets liés aux approches par défaut. Cependant, même avec l’expertise requise, les LLMs ont tendance à générer des réponses inexactes ou inventées, à revenir à leurs réglages par défaut, rendant les reformulations successives presque inévitables, parfois jusqu’à provoquer un effondrement du modèle. Par conséquent, cette « attraction par défaut » devient un paramètre dont il faut systématiquement tenir compte. (Paschalidis 2025)
Si une formulation est fortement présente dans le corpus d’entraînement est-ce que c’est nécessairement la meilleure ? L’approche par défaut vaut-elle pour tous les contextes ?
Des ‘petites’ corrections finales ?
Currently, academic publishers only allow the use of ChatGPT and similar tools to improve the readability and language of research articles. However, the ethical boundaries and acceptable usage of AI in academic writing are still undefined, and neither humans nor AI detection tools can reliably identify text generated by AI. (Homolak 2023)
It is being increasingly observed that content generated by ChatGPT is going undeclared and undetected, resulting in its appearance in articles published in scholarly journals. […] The general policy among publishers states that AI tools must not be used to create, alter or manipulate original research data and results (Elsevier., 2023; Roche, 2024).(Strzelecki 2025)
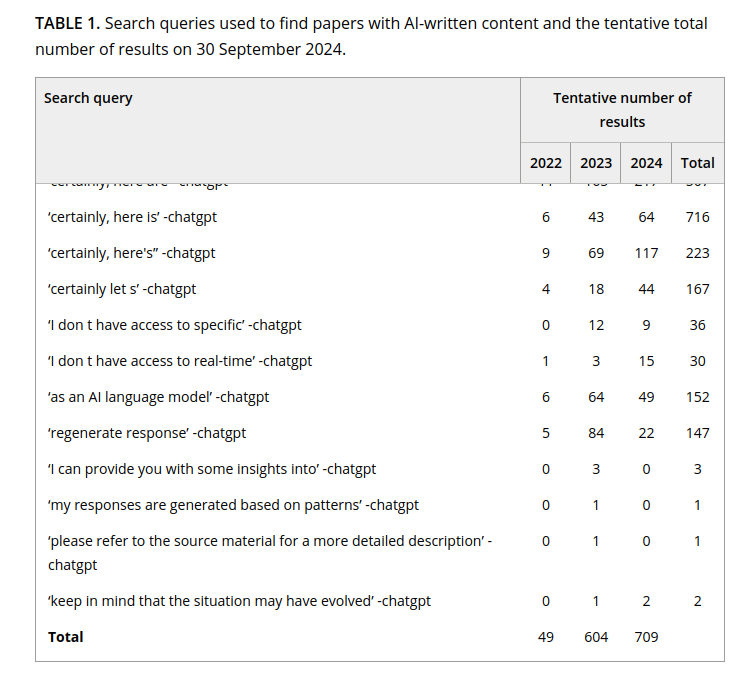
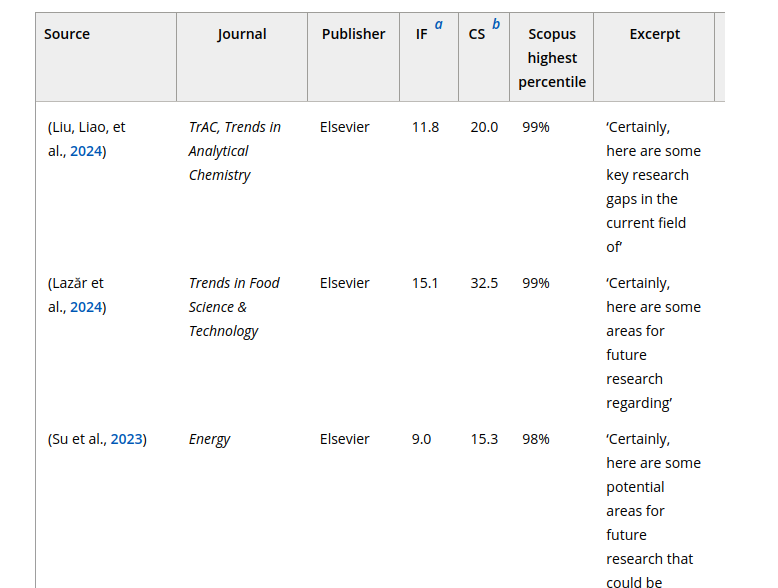
Est-ce que négliger la correction revient à négliger la lecture et l’écriture ?
Les outils historiques (francophones)
Sources sur les technologies d’Antidotes :
Reformulation et IA (décembre 2023)
ChatGPT peut-il remplacer Antidote ?(https://www.antidote.info/fr/blogue/astuces-et-conseils/chatgpt-peutil-remplacer-antidote)
Une combinaison d’outils spécialisés et utilisant des techniques diverses.
ProLexis (pas de vidéos youtube depuis 3 ans, ProLexis7) Outil professionel, analyseur syntaxique, interface à l’ancienne, powerpoint à l’ancienne.
Les nouveaux outils
EditPad : AI detector, humanize AI text, Plagiarim checker, paraphrasing tool, story generator, text summarizer, AI essay writer etc. Probablement juste ChatGPT hooked à une interface avec un system-prompt. Apparamment mauvais according to Bordalejo et al. (2025)
screenshot editpad
Corriger = masquer que le texte ne vient pas d’une machine, ou chercher à le détecter?
Writefull: Title generator, Abstract generator, paraphraser, academizer.
Effet de mode = disparition et apparition de solutions miracles (down le 22 septembre, up le 30 septembre mais bug)
Grammarly donne une note à partir des critères de formalité, 4 niveaux : correctness (corrige erreurs grammaticales), clarity (reformulation) engagement (option payante), delivery (payant), plagiarism detection (payant). Option ‘generative AI’ avec des prompts pre-écrits qui restreignent l’usage. Et un browser plugin qui permet de s’en servir avec tous les sites google (docs, gmail, youtube comments).
improve est une option liée à “Generative AI” juste ‘améliorer’.
“Is QuillBot considered AI writing? 2 years ago Updated Everyone’s talking about AI writing these days, and debate over its use — and misuse — rages. QuillBot has helped you grow and improve as a writer, but you may wonder if using it is considered AI writing. Good question. The short answer is “no.” QuillBot’s tools have specific uses, such as correcting grammar or paraphrasing sentences. It’s up to you to use the feedback and suggestions to create content that is solely your own. ChatGPT and similar AI writers, on the other hand, can generate essay-length text from a few prompts. That writing can then be presented with no changes. Since QuillBot is not considered AI writing, most plagiarism checkers will not flag its use.
That said, we make no guarantees if someone uses QuillBot on text generated by a tool like ChatGPT. Why not play it safe and craft the content yourself? (With QuillBot’s help, of course!)
