Atelier 1 : Connaître et évaluer les systèmes d’automatisation complexes pour les revues

2026-02-12
Applications de chat actuelles
ChatGPT, Le Chat de Mistral etc. sont des applications qui interagissent avec un LLM (GPT5.2, Mistral). Ce qui est envoyé comme requête est appelé un prompt. Le prompt ne contient pas que la requête de l’utilisateur.
Dans ce prompt, on trouve un ensemble d’instructions préliminaires (le system prompt) et d’informations complémentaires comme l’historique des échanges (chat history).
Depuis décembre 2024, le Model Context Protocol (MCP) permet l’intégration modulaire de l’interface de chat à d’autres fonctionalités des applications grands publics de chat -> interaction avec un agenda sur le cloud, des sites marchands etc.
Définition hypée des IA agentiques
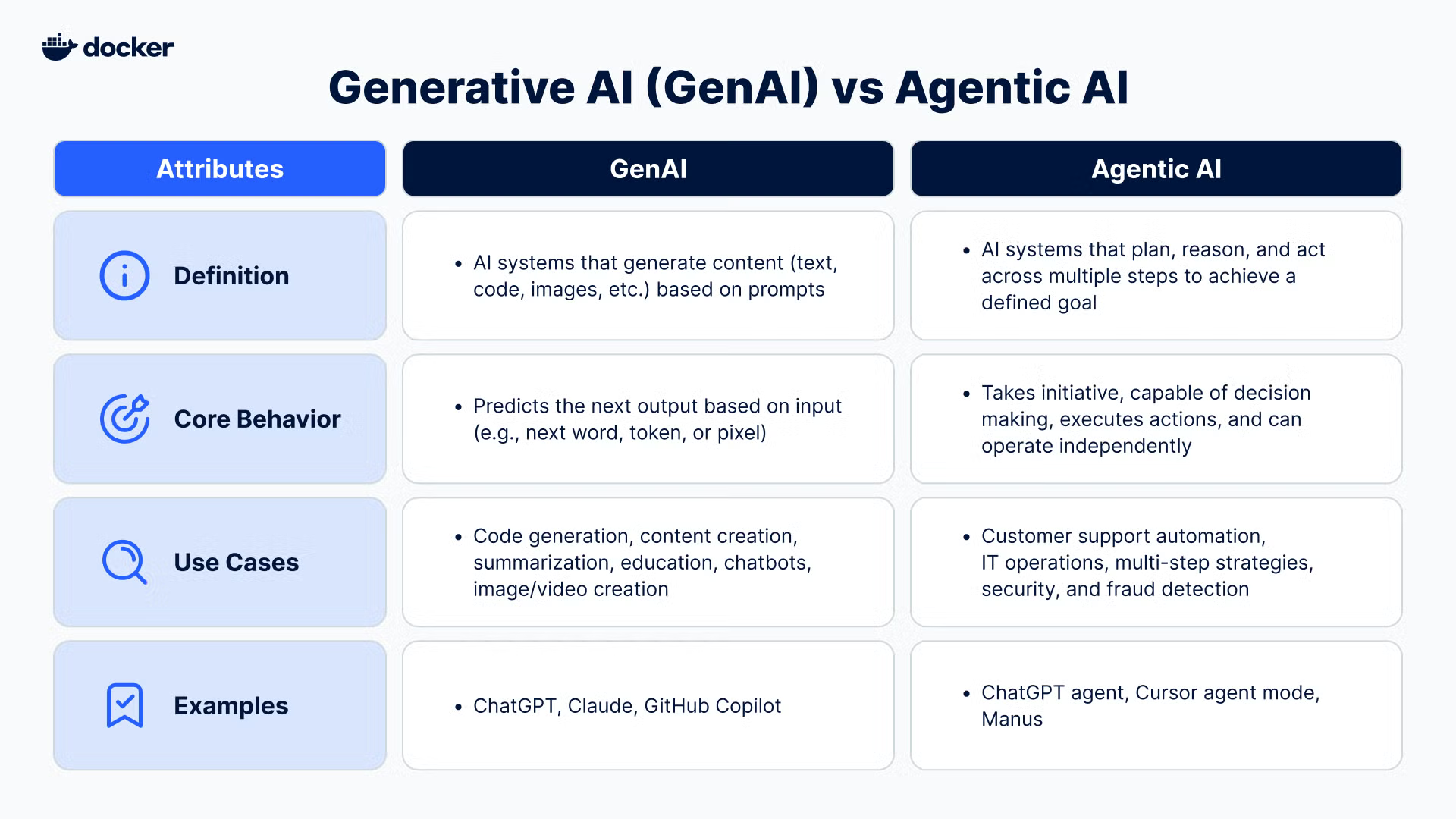
Description des IA agentiques par Docker (Irwin and Xu 2025)
L’agent a pour objectif de compléter une tâche de manière “autonome” c’est-à-dire sans intervention d’un humain, sans relance de l’utilisateur ou du dev. On parlera de système agentique quand plusieurs agents interagissent.

Des Agents en pagaille
Il existe plusieurs architectures permettant de spécialiser des agents : orchestration par un LLM, architecture séquentielle ou parallèle, design en boucle etc.
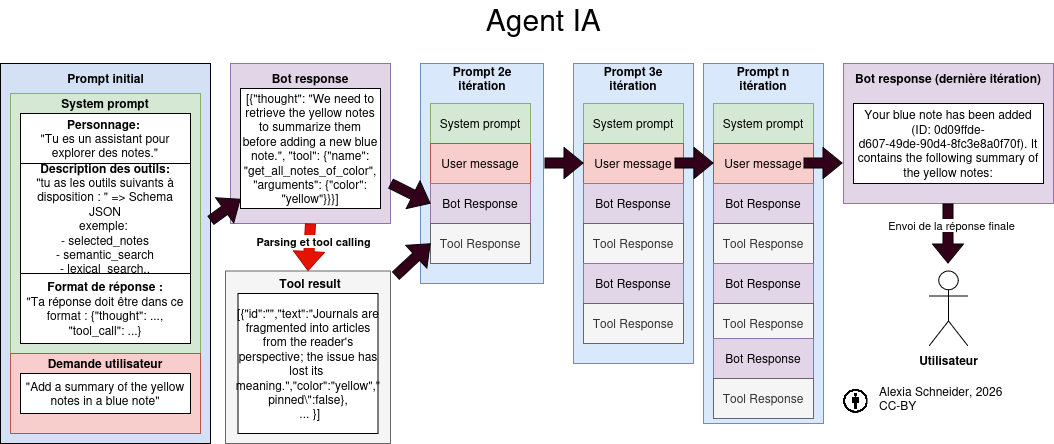
Schéma de l’architecture d’un agent IA