Intro
Plan
- Présentation de la série d’atelier
- Qu’est-ce que l’IA ?
- Intérêt d’étudier l’IA pour les SHS
- Retours historiques
- Typologie des IA
- Cas d’usage et modélisation experte (ELIZA)
- Cas d’usage et modélisation distributionnelle/vectorielle (vectorisation et prédiction)
- Les LLMs
- Usages des LLMs hors chatbots (demo)
- LLMs et chatbots (Duck.ai + Ollama)
- Conclusions
Présentation et objectif des ateliers
Format : 4 séances de 2heures, sans inscription, participation libre (à justifier pour le certificat des Humanités Numériques)
Théorie et pratique en alternance au cours des deux heures.
Objectifs de la série d’atelier :
- Comprendre les fondamentaux de l’IA et son histoire
- Obtenir des notions critiques sur le fonctionnement profond des outils
- Tester et s’approprier des outils d’IA
- Maîtriser le vocabulaire de la discipline
Objectifs de cet atelier :
- Comprendre les différentes formes d’IA
- Comprendre les enjeux liés à l’utilisation des LLM
- Utiliser de l’IA en dehors d’une interface de tchat.
- Tester les paramètres des chatbots
- Installer localement des modèles de langue.
Qu’est ce que l’IA ?
Tout et rien : exemples : chatbot, détection sur des imageries médicales, HTR, DeepBlue.
le dernier mot à la mode. Le ‘numérique’ des années 2020. (Vitali-Rosati 2025).
Qu’est-ce que l’IA ?
Définition pratique : “un programme informatique qui effectue une prédiction.”
L’IA et les SHS
À quoi sert d’étudier l’IA pour les chercheur.se.s en SHS ?
L’IA et les SHS
À quoi sert d’étudier l’IA pour les chercheur.se.s en SHS
L’IA et les SHS
Que peuvent faire les SHS pour l’IA ?
- participer à la réflexion actuelle sur son utilisation :
- positionnements de revues et de conférences (pose un cadre, parfois un précédent)
- proposer une théorie critique de l’IA décentrées de l’effet ‘benchmarking’ (i.e. comparaison des modèles ou des entreprises qui les mettent à disposition)
- proposer une avis sur l’utilisation de ces outils qui soit propre à sa discipline (ex: distinguer des usages en fonction des besoins particuliers de son domaine).
Exemples de prises de position
Both SUP and JHUP have increasingly embraced, tested, and deployed some AI tools and policies. Barbara has been clear in her support of responsible uses of AI and the necessity of leveraging these early days to stake a claim within the quickly evolving landscape. Like SUP, JHUP is building and testing its own tools for marketing, accessibility, and analytics, efforts which place our presses in a position to potentially build services that might in the future even benefit other university presses. (Mulliken 2025)
we offer recommendations for citing generative AI, defined as a tool that “can analyze or summarize content from a huge set of information, including web pages, books and other writing available on the internet, and use that data to create original new content” (Weed). (“How Do I Cite Generative AI in MLA Style?” 2023)
The uncomfortable truth for researchers and publishers who oppose AI slowly taking over human review is that they might not be able to prevent it. Should a researcher use AI to write the first pass of peer review and not disclose it — in contravention of publisher guidelines — that might not be detectable, says Hosseini, who is also one of the editors of the journal Accountability in Research. And if AI reviews become widespread, that could change the practice of science, says Priem. “Every researcher can run their own bespoke review service over the preprint/dataset landscape, flagging/extracting only the science they care about (at any “quality” level) they want that day,” he wrote on X earlier this year. That could start to eat into the roles of journals, by taking away the certification that peer review mediated by journals provides, he says. (Naddaf 2025)
- Building critical AI literacies is a process of empowerment that enables students and citizens to exercise independent judgment about whether or if to use this very new and largely untested commercial technology. (rutgersCriticalAILiteracies2024?)
Brève histoire de l’IA et des applications de linguistique computationnelle (pt. 1)
1940s : Science-fiction et roman d’Isaac Asimov Runaround en 1942.
Turing (1950) : ‘can machines think?’
‘intelligence artificielle’ : 1956
« The word Artificial Intelligence was then officially coined about six years later, when in 1956 Marvin Minsky and John McCarthy (a computer scientist at Stanford) hosted the approximately eight-week-long Dartmouth Summer Research Project on Artificial Intelligence (DSRPAI) at Dartmouth College in New Hampshire. » (Haenlein and Kaplan 2019, 7)
1966 : ELIZA (Weizenbaum 1966)
1990-2000s : pic des systèmes experts et des arbres de décision. DeepBlue d’IBM (Campbell, Hoane, and Hsu 2002).
Brève histoire de l’IA et des applications de linguistique computationnelle (pt. 2)
2010s : pic des systèmes d’IA avec une modélisation distributionnelle du language (vecteur). Word2Vec (Mikolov et al. 2013), GloVE (Pennington, Socher, and Manning 2014). Parmi les avancées majeures de cette modélisation on compte le mécanisme d’attention (Vaswani et al. 2017) et l’encodage bidirectionnel BERT (Devlin et al. 2019) qui permettent des modèles très performants comme le GPT-3 d’OpenAI (Brown et al. 2020).
Actuellement : tendance à l’hybridation de ces modèles : Neuro-Symbolic Integration, Semantic Web Machine Learning (Marcus 2020; Breit et al. 2023)
Typologie de l’IA
Approche experte ou modèle symbolique : modélisation d’un programme à partir de règles précises. Les règles doivent être applicables à de nouvelles données pour faire une prédiction.
Approche inductive ou modèle d’apprentissage machine (machine learning) : modélisation d’un programme à partir d’un grand volume de données. Ce sont les motifs de répétitions qui permettent à la machine d’émettre une prédiction.
Ce qu’il faut retenir
- L’IA réfère à plusieurs type de modélisations pour la prédiction : une approche déductive et une approche inductive.
- On parle ‘des saisons’ de l’IA pour évoquer l’attrait public de la discipline et son avancée depuis les années 1950.
- Par conséquent, certaines approches attirent l’attention à un moment donné, actuellement IA = chatbot voire ChatGPT.
- L’IA réfère à des algorithmes qui permettent d’automatiser une prise de décision et pas seulement à des programmes de génération textuelle.
Partons d’un exemple
Objectif : obtenir un programme capable de classer une phrase selon une thématique prédéfinie.
Exemple : Classification d’un texte soit en “parle de fruit” soit en “ne parle pas de fruit”.
Vocabulaire :
document : ici une phrase
classes : ensemble thématique de la classification. Ex : “fruit” et “non fruit” pour la classification binaire de notre exemple.
jeu de données : ensemble des documents
apprentissage supervisé : méthode d’apprentissage machine à partir de classes connues.
apprentissage non-supervisé : méthode d’apprentissage machine sans connaître les classes à l’avance : a pour objectif de déterminer les caractéristiques discriminantes d’un jeu de données.
vérité de terrain ou ground truth : annotation effectuée par un humain sur l’ensemble du jeu de données.
Modéliser une approche experte
- faire appel à un expert : un humain pour déterminer les règles qui définissent ce qui est une phrase parlant de fruits.
- exemple de règle possible : liste de mots comme ‘pomme, pommes, banane, poire etc.’ ordre des mots ou POS pour distinguer ‘orange’ couleur du fruit par exemple.
Une approche qui sembler simpliste en apparence mais qui :
- peut s’avérer très complexe (ex: traduction)
- est la base de systèmes très performants
- entre dans une logique de lazy computing (Fujinaga 2025)
- révèle les tâches de bas niveau pour passer d’une chaîne de caractères à un ensemble de caractéristiques : tokenisation, POS-tagging.
Exemple d’un programme conversationnel /génération textuelle avec une approche experte ELIZA
Try it yourself : ELIZA
Eliza is a pattern-matching automated psychiatrist. Given a set of rules in the form of input/output patterns, Eliza will attempt to recognize user input phrases and generate relevant psychobabble responses. Each rule is specified by an input pattern and a list of output patterns. A pattern is a sentence consisting of space-separated words and variables. (Connelly n.d.)
Exemple de literate programming (Knuth 1984) :
Approche inductive : la modélisation vectorielle et le machine learning
1e étape Modélisation des données
- Constitution d’un corpus : obtenir un ensemble important de documents.
- Attribution d’une classe à chaque document : annotation par un humain/expert, ground truth ou vérité de terrain.
- Encodage : Comptage des tokens dans l’ensemble du jeu de données et dans chaque phrase/document.
- On obtient une représentation vectorielle = coordonnées dans un espace vectoriel à n dimensions.
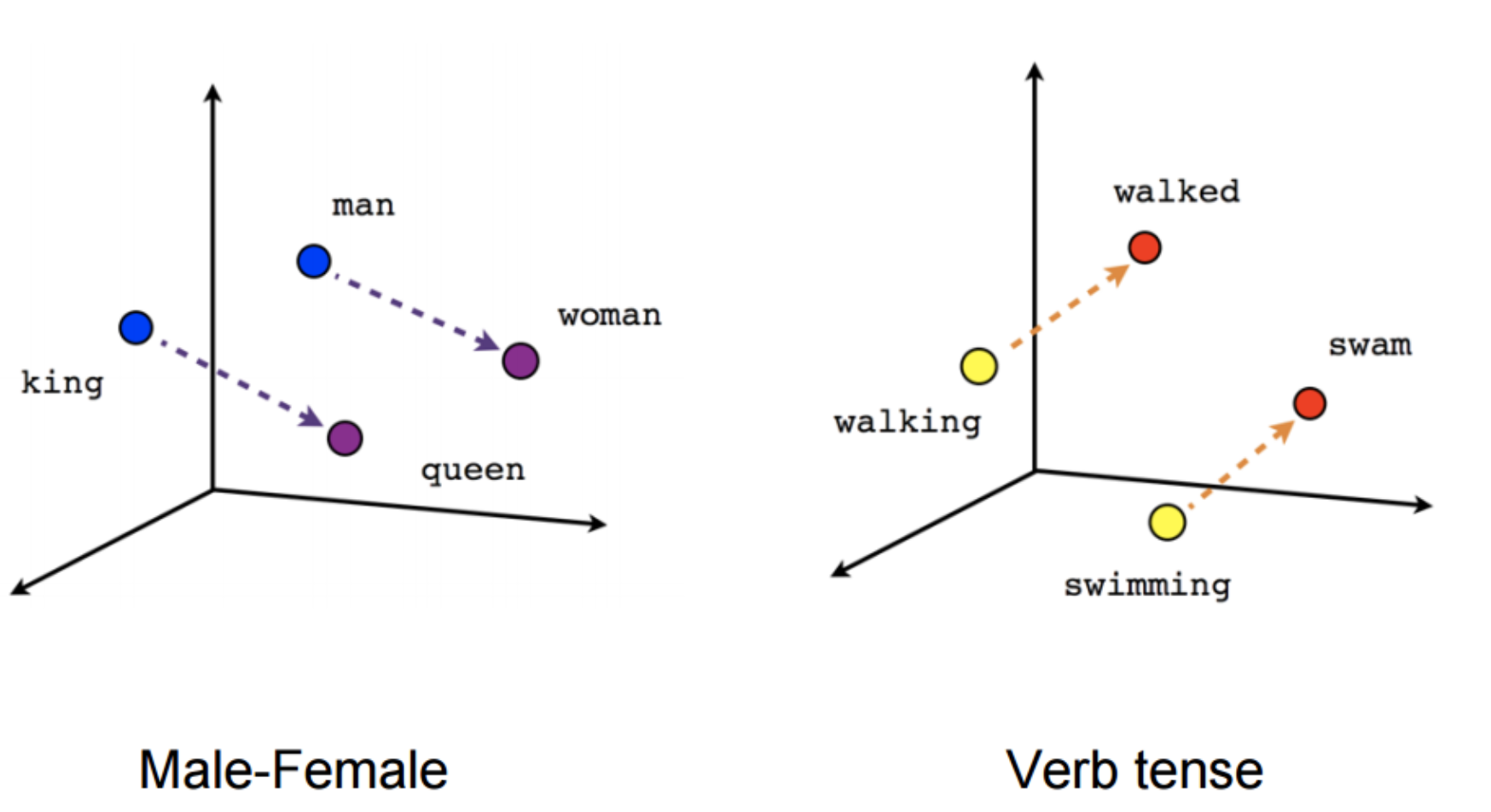
2e étape Détermination de la logique de prédiction
Différentes logiques permettent de distinguer les données entre elles. Quelques exemples d’apprentissage machine classique :
- K-Nearest Neighbor -> le token apartient à la même classe que ses voisins (au nombre K)
- Arbre de décision -> on construit un arbre de questions fermées qui dessine le jeu de données.
- Regression logistique -> une ligne sépare l’espace vectoriel entre les deux classes
3e étape Apprentissage
- Division du jeu de données en données d’entrainement et données de test.
- Calcul des poids de chaque token (régression logistique ou arbre de décision) sur les données d’entrainement.
- Prédiction sur les données de test
- Comparaison avec la vérité de terrain
- Ajustement des poids : réitération de l’apprentissage si les prédictions sont insatisfaisantes. (Cette étape est très énergivore)
4e étape Evaluation ou utilisation du modèle sur de nouvelles données
- De nouvelles données (données d’évaluation sur une phase expériementale) qui n’ont jamais été vues par la machine, sont vectorisées aussi.
- Le programme entraîné effectue ses prédictions sur ces données.
Les LLMs
Exemple de LLMs : GPT-4, Mixtral, Gemini, Llama, Qwen, DeepSeek etc.
Large Language Models : 1. Encodage : Word embeddings ou plongement de mots obtenu par rapport à sa fréquence d’apparition en contexte avec chacun des autres mots de la langue à partir d’un volume de données textuelle gigantesque. Modèles de type BERT : encodage bilatéral avec méchanisme d’attention. 2. Spécialisation du modèle sous forme de couches neuronales pour une tâche ou une fonction précise. 3. Query et calcul pour chaque donnée en entrée du token le plus probable en sortie.
En résumé
Modèle de langue = modélisation de la langue dans son ensemble + capacité de prédiction.
Les LLMs font de la prédiction de token :
- la génération de texte n’est pas la première ni la seule utilisation des LLMs.
- soliciter un LLM pour générer un texte demande de recalculer le token le plus probable à chaque token -> coût énergétique important.
LLMs et chatbot
Parce que les LLMs sont lourds (plusieurs Gigas) et parce qu’il est coûteux en énergie d’effectuer les calculs qui permettent de déterminer le prochain token (plusieurs GPU), l’usage le plus courant des IA générative est via un site qui va interroger le modèle sur un serveur distant. C’est la forme ChatGPT, Mistral.ai, etc.
Duck.ai
duck.ai permet de comparer des modèles en interfaces chat tout en conservant des données privées.
Circuit Tracing
Interprétation du méchanisme par lequel un modèle effectue la prédiction d’un modèle à partir d’un prompt.
Neuronpedia ‘circuit tracing’ demo : Explication du processus interne d’un LLM pour la prédiction d’un token à partir d’un prompt.
Ollama
Il est possible de faire tourner un SLM (small language model) localement. Pour ce faire : ollama est une bibliothèque qui permet de télécharger et d’utiliser localement un LLMs.
Installation et utilisation de Ollama
Utilisation de Ollama en invite de commande
Via l’invite de commande
ollama run llama3.2 -> télécharge et lance le modèle.
““” -> pour des instructions longues
/show info -> information sur le modèle téléchargé
ollama list -> liste des modèles téléchargés et utilisables
ollama rm llama3.2 -> supprime un modèle
Paramètres d’un modèle
- Le seed (nombre que l’on peut choisir): les LLMs ont une variable aléatoire au moment de l’encodage des données et au moment du requêtage : le seed permet d’utiliser toujours le même ordre aléatoire, càd d’obtenir pour un même prompt toujours la même réponse. Enjeu de reproductibilité.
- La température (valeur de 0 à 1): détermine le degré d’utilisation de la variable aléatoire. Une température élevée signifie que le modèle sera plus “créatif” car il donnera plus probablement un token qui a une probabilité absolue moindre dans son contexte.
- top_k (valeur de 0 à 100): variable qui réduit la probabilité de générer des tokens absurdes. Une valeur élevée donne des réponses plus variées et une valeur basse des réponses plus conservatrices. (Défaut 40)
- top_p (valeur de 0 à 1): Fonctionne avec le top_k. Une valeur haute donne un texte varié, une valeur basse, un texte conservateur. (Défaut: 0,9)
Source : Documentation Ollama
Model Steering
Reconduire un modèle consiste à lui fournir des ordres qui vont modifier son comportement pour toutes les interactions.
Steer model interactively on Neuronpedia
Créer un nouveau document ‘Modelfile’ sans extension.
Linux : cat > Modelfile puis CTRL+C :
FROM llama3.2 PARAMETER temperature 1 top_k 100 top_p 1 seed 17 SYSTEM “Tu es un chien”
puis CTRL+SHIFT+D et CTRL+D
Windows cmd (Win+R): echo 'FROM llama3.2 PARAMETER temperature 1 top_k 100 top_p 1 seed 17 SYSTEM "Tu es un chien"' > Modelfile (CTRL+SHIFT+D)
Ou c/c manuellement :
FROM llama3.2 PARAMETER temperature 1 top_k 100 top_p 1 seed 17 SYSTEM “Tu es un chien”
ollama create chien -f Modelfile
ollama run chien
Limites des interfaces de chat
- les chatbots ont des limites : on peut ‘hacker un LLM’ avec du prompt injection ou autres techniques de jailbreaking.
Hidden prompts reportedly were discovered in at least 17 academic preprints on arXiv that purportedly instructed AI tools to deliver only positive peer reviews. The lead authors are reportedly affiliated with 14 institutions in eight countries, including Waseda University, KAIST, Peking University, and the University of Washington. The alleged concealed instructions, some of which were reportedly embedded using white text or tiny fonts, were purportedly intended to influence any reviewers who rely on AI tools. (https://incidentdatabase.ai/cite/1135)
- il n’y a pas d’hallucinations, toutes les générations produites par un LLMs ont la même teneur de vérité du pdv de l’outil : le modèle ne peut pas évaluer sa réponse à l’aune d’une ground truth comme dans sa phase d’entraînement.
Études critiques de l’IA
Discipline émergeante : Critical AI revue lancée en 2023.
Pistes de réflexions :
- Uniformisation des pratiques et des modes de pensées : l’interface de chat est une façon de formaliser son problème, quid de la recherche de solution en interrogeant des moteurs de recherche, des bases de données ou des archives spécialisées ?
- Derrière l’apparente accessibilité de l’interface de chat, est-ce qu’on ne risque pas de creuser l’écart de la littératie numérique ?
- Est-ce que ces connaissances spécifiques, comme celles du code, qui impliquent des capacités de raisonnement alternatives, ne risquent pas de se retrouver suelement dans une forme d’élite intellectuelle ?
- Comment peut-on définir une littéracie propre aux outils d’IA ?
- Quelle posture adopter ? Faut-il interdire l’usage dans la recherche ou l’enseignement, obliger une déclaration d’utilisation/citation ou encore laisser faire selon les usages et opter pour une approche pédagogique ?
Ce qu’il faut retenir
- L’IA est amalgamé aux LLMs et en particulier aux interfaces de chatbots mais cela recouvre en réalité des processus algorithmiques variés.
- L’histoire de l’IA a montré qu’il y a des phases tant dans les approches valorisées que dans l’approbation de l’‘intelligence artificielle’ opposée à l’intelligence humaine.
- un système expert (symbolique) peut être aussi complexe et ‘intelligent’ qu’un LLM.
- Les systèmes d’IA n’ont pas de connaissance du réel et sont des modèles purement probabilistes.
- Les ‘halllucinations’ ne sont pas des anomalies, ce sont des erreurs que l’on qualifie a postériori comme telles.
- Les systèmes inductifs sont appropriés pour certaines tâches : classification, production de résumé. Leur point fort reste leur adaptabilité à de nouveaux contextes.
- Les chatbots sont des interfaces qui permettent un échange homme-machine en langue naturelle : l’exploitation des capacités inductives d’un LLMs ne nécessite pas de passer par une telle interface. Ex : classification, processus expérimental plus adapté à une utilisation sans cette interface.
Ressources vues pendant l’atelier
Duck.ai : Comparaison de modèles sous forme de chatbot et paramétrage.
Ollama et documentation : Téléchargement de LLM localement. Possibilité de steer un modèle.
Neuronpedia ‘steer’ demo : Comparaison d’un modèle qui a été ‘redirigé’ ou non.
Neuronpedia ‘circuit tracing’ demo : Explication du processus interne d’un LLM pour la prédiction d’un token à partir d’un prompt.
spaCy : Librairie Python spécialisée dans le Traitement Automatique des Langues : implémentation dans un programme de LLM (modèles en français disponibles).
Incident Database AI : Résumé des incidents et controverses relevées dans la presse lié aux IA (en anglais).
Critical AI journal : Revue